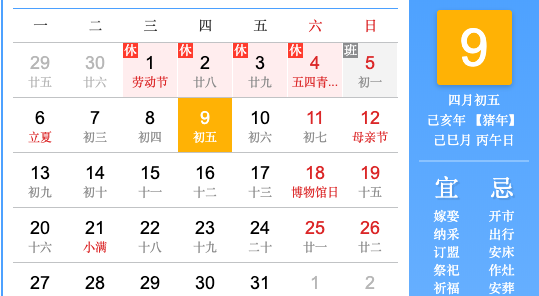
背景
曾几何时,有莫有觉得自己的博文url过于繁琐,而且博文名称包含中文,发送链接变成unicode编码,很不友好。那好,hexo-abbrlink插件解决url带来的难题。

问题简述
博客已经托管在github有一段时间了,有天同事想看看,url发送给同事,但是随便点开了一个文章,居然404,逗我。。。。。。why?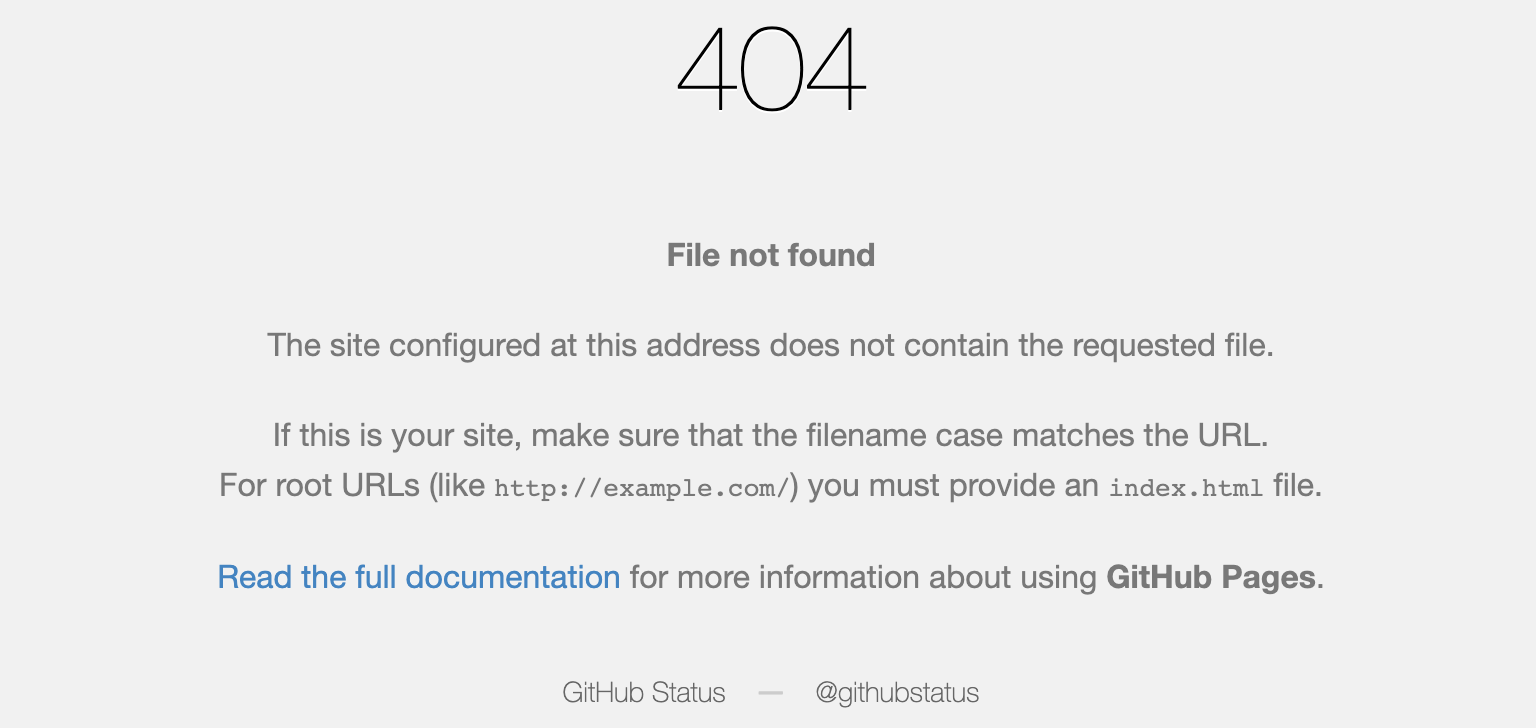
博客运行了很久,也写了不少文章,有的时候需要回去翻自己写过的文章找点东西,比较麻烦,而且也看了别人的博客好多都有一个🔍搜索功能,针对于我使用的Hexo+Next版本也增加一个搜索功能。但是,在实现的过程中遇到了一些坑,想必也会有人跟我一样,于是写下来与大家分享。
身为一位程序员,没事的时候爬爬糗百笑话、淘宝女郎、小片片。。。。。。有点邪恶了。反正关于爬虫,相信很多人都不陌生,本人没事的时候也写写爬虫的小项目,写过天气报警、糗百笑话、美女图片。。。。。。,后续会在博客中挑选个例子写出来。
关于数据采集,用Python去写爬虫程序,主要涉及2个主要的Package:Requests && BeautifulSoup。
| 包名 | 功能说明 |
|---|---|
| Requests | HTTP获取源数据 |
| BeautifulSoup | 解析 && 获取目标数据 |
关于这2个爬虫利器分为上下篇进行讲解,本篇先介绍Requests,主要功能是进行数据的获取。